Code
# Load packages and data
library(tsissm)
library(xts)
library(data.table)
library(future)
library(progressr)
library(copula)
library(tsmethods)
data("gas", package = "tsdatasets")
n <- NROW(gas)
train <- gas[1:(n - 52)]
test <- tail(gas, 52)Real world data rarely has clean patterns from which we can quickly identify the data generating process (DGP). It is messy1 and contains anomalies which often times cloud the true signal. Even worse, even if the data appears regular, there are never any guarantees that the future will follow the past.
Choosing a best model is an almost impossible task. At best, a model we choose represents some approximation to the true DGP of the process under consideration. The observed history of most series will usually indicate an overlap between many generating processes when uncertainty is taken into account.
One approach to dealing with this problem is to cast a wide net by combining multiple models together in an ensemble. The question of how to combine them will not be addressed here, but suffice to say that unless we have really strong priors on ranking preference, we should really use an equal weight allocation as its the optimal choice under high uncertainty (see for example Pflug, Pichler, and Wozabal (2012)).
The particular problem we address in this article is one of ensembling for GDP uncertainty using a common information set (the series’ own history). This is separate from ensembling in the presence of multiple independent predictors which is a slightly different problem which has been addressed extensively in recent years in the machine learning community.
When ensembling predictive distributions on the same series, it’s important to consider how to ensemble them given the fact that they are unlikely to be independent.
This can be seen from an investigation of the model residuals and their correlations. As demonstrated in the tsmethods ensembling section, we can make use of a copula to generate correlated uniform variates which can then be passed to the predict function of any of the tsmodels packages which then convert them into \(N(0,\sigma)\) innovations. In this way, the conditional 1-step ahead errors will at least retain their dependence and the distributions will be ensembled in a more accurate way. If instead we were to assume independence, then the coverage of the ensembled predictions would significantly underestimate the true coverage as a result of assuming that the off diagonals of the covariance of series residuals were zero.
A similar argument follows when ensembling for the purpose of aggregation, which is more typical in hierarchical forecasting approaches.
For the purpose of this article, we use the gas data set, which is available in the tsdatasets package, representing the US finished motor gasoline products supplied (in thousands of barrels per day) from February 1991 to May 2005. This is a weekly data set with seasonal and trend components.
While we could consider multiple different models, for this example we only consider the rather flexible innovations state space model (issm) with level, slope, trigonometric seasonality and ARMA terms. Whether to include or not the slope, slope dampening, the number of harmonics and the number of ARMA terms is what will determine the models we use for ensembling. To this end, we will enumerate a space of combinations using the auto_issm function to obtain a selection matrix ranked by AIC. We then choose the top 5 models for ensembling.
We split out data into a training set and leave a year (52 weeks) for testing.
# Load packages and data
library(tsissm)
library(xts)
library(data.table)
library(future)
library(progressr)
library(copula)
library(tsmethods)
data("gas", package = "tsdatasets")
n <- NROW(gas)
train <- gas[1:(n - 52)]
test <- tail(gas, 52)plan(list(
tweak(remote, workers = "home_server"),
tweak(multiprocess, workers = 60)
))
mod <- auto_issm(train, slope = c(TRUE, FALSE), seasonal_damped = c(TRUE, FALSE),
seasonal = TRUE, seasonal_frequency = 52,
seasonal_type = "trigonometric", seasonal_harmonics = list(4:12),
ar = 0:5, ma = 0:5, return_table = TRUE, trace = FALSE)
plan(sequential)print(head(mod$selection))## iter slope slope_damped seasonal ar ma K1
## <int> <lgcl> <lgcl> <lgcl> <int> <int> <int>
## 1: 941 TRUE FALSE TRUE 1 4 12
## 2: 956 TRUE FALSE TRUE 0 5 12
## 3: 958 TRUE TRUE TRUE 1 5 12
## 4: 776 TRUE FALSE TRUE 0 1 11
## 5: 800 TRUE FALSE TRUE 2 2 11
## 6: 773 TRUE FALSE TRUE 5 0 11
## AIC MAPE
## <num> <num>
## 1: 11879.73 0.01920864
## 2: 11880.63 0.01911436
## 3: 11914.47 0.01938119
## 4: 11924.07 0.01987139
## 5: 11933.70 0.01979659
## 6: 11934.09 0.01974837The returned selection table shows the list of different model choices ranked from lowest to highest AIC for the training data used. We proceed by calculating the correlation of the model residuals for use in generating random uniform variates from a Normal Copula.
mod_list <- lapply(1:5, function(i){
spec <- issm_modelspec(train, slope = mod$selection[i]$slope, slope_damped = mod$selection[i]$slope_damped,
seasonal_frequency = 52,
seasonal = mod$selection[i]$seasonal, seasonal_type = "trigonometric",
seasonal_harmonics = mod$selection[i]$K1, ar = mod$selection[i]$ar,
ma = mod$selection[i]$ma)
mod <- estimate(spec)
return(mod)
})
r <- do.call(cbind, lapply(1:5, function(i){
residuals(mod_list[[i]], raw = TRUE)
}))
colnames(r) <- paste0("model",1:5)
C <- cor(r, method = "kendall")
print(C, digits = 2)## model1 model2 model3 model4 model5
## model1 1.00 0.82 0.80 0.75 0.77
## model2 0.82 1.00 0.96 0.84 0.87
## model3 0.80 0.96 1.00 0.85 0.87
## model4 0.75 0.84 0.85 1.00 0.95
## model5 0.77 0.87 0.87 0.95 1.00We generate the 5000 (samples) by 52 (forecast horizon) random draws from the Normal Copula and pass them to the predict function. All models in the tsmodels framework accept either uniform (innov_type = “q”), standardized (innov_type = “z”) or non-standardized innovations (innov_type = “r”). In the former case the quantile transformation will be applied to transform the uniform values to standard normal innovations. The resulting standardized innovations are then re-scaled to have standard deviation equal to that of the estimated models’ residuals.
cop <- normalCopula(P2p(C), dim = 5, dispstr = "un")
U <- rCopula(52 * 5000, cop)
predictions <- lapply(1:5, function(i){
predict(mod_list[[i]], h = 52, nsim = 5000, innov = U[,i], innov_type = "q")
})The final step is to ensemble the forecasts for which we make use of the functionality from the tsmethods package which takes a list of tsmodel.predict objects and ensembles them.2
weights <- rep(1/5, 5)
spec <- ensemble_modelspec(predictions)
p <- tsensemble(spec, weights = weights)
# infuse some additional information into the ensembled object so we can use
# other methods on this
class(p) <- c("tsissm.predict", class(p))
p$frequency <- 52
predictions[[6]] <- pComparing our predictions across each of the 5 models and the ensembled one, against the testing data set, we observe some interesting, but not surprising findings. The top model selected by AIC during the training phase now has the second worst performance in the testing phase, whereas the 4th worst model by AIC in the training now has the best performance in the testing phase. This should make clear the comments made in the introduction about future uncertainty. The ensemble model sits right in the middle, coming in third in terms of MAPE, and second in terms of the distribution calibration metrics (MIS and CRPS).
prediction_metrics <- do.call(rbind, lapply(1:6, function(i){
tsmetrics(predictions[[i]], actual = test, alpha = 0.1)
}))
rownames(prediction_metrics) <- c(paste0("model",1:5),"ensemble")
prediction_metrics## h MAPE MASE MSLRE BIAS
## model1 52 0.02069121 0.5739093 0.0006255166 -0.0014976744
## model2 52 0.02194529 0.6087442 0.0007034767 -0.0004547551
## model3 52 0.02248476 0.6237508 0.0007739192 -0.0063832761
## model4 52 0.02847264 0.7895135 0.0011947730 -0.0030526928
## model5 52 0.02034886 0.5643485 0.0006353729 -0.0006761913
## ensemble 52 0.02087266 0.5792841 0.0006744860 -0.0024129179
## MIS CRPS
## model1 913.8911 130.4708
## model2 1044.9567 140.3905
## model3 1121.0820 147.7341
## model4 1321.6796 180.0566
## model5 1056.5165 134.4742
## ensemble 1031.4426 136.0655plot(p, n_original = 52*4, xlab = "", main = "Ensemble GAS Prediction",
gradient_color = "yellow", interval_color = "orange")
lines(index(test), as.numeric(test), col = "violet", lwd = 2)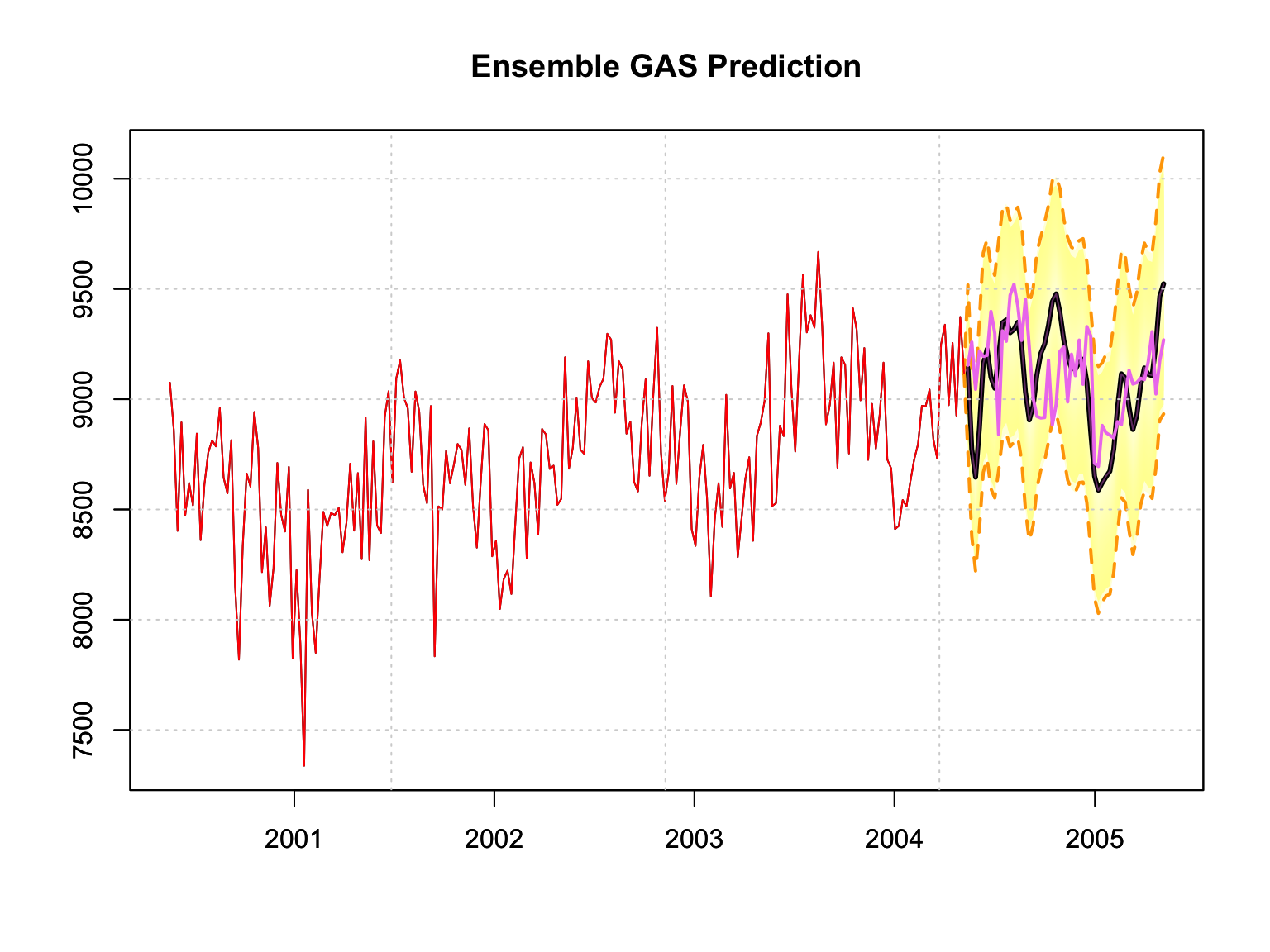
Because the models were all estimated with the same transformation3, their state decompositions can also be ensembled. This could be particularly useful should custom views need to be incorporated into the prediction, which is usually done on the Trend component or the growth rate, allowing one to rebuild the full predictive distribution after intervening in some part of the state decomposition.
There should be no doubt about the value of ensembling. The key takeaway is: When in doubt, ensemble.
@online{galanos2022,
author = {Galanos, Alexios},
title = {Casting a Wide Net: Ensembling of Predictions},
date = {2022-05-15},
url = {https://www.nopredict.com/blog/posts/2022-05-14-model-ensembling/},
langid = {en}
}